REPL上での上付・下付文字やギリシャ文字っぽい文字のLaTeXっぽい入力は非常に便利であるが, GoogleIMEのローマ字テーブルカスタマイズでT-codeの漢直っぽいことを実現してきた私としては,わりと簡単ではないかと思った。
まず,漢直と同じようにローマ字テーブルをいじるのは,
ローマ字に半角英数の大文字が含められないという制限があって即座にダメと分かる。
\Pi → Πという変換テーブルが組めないのだ。また,一意に決まらないといけないので,
\^a → ᵅと\^alpha → ᵅのどちらか一方しかローマ字テーブルでは有効にならない。
ということで早々と断念したのだが,
ここでふと頭の中に斉藤和義の「僕の踵はなかなか減らない」の曲調で 「♪日本人なら(IMEユーザー辞書)登録したまえ」(原曲は「♪日本人なら目で話したまえ」) が鳴り響いて, 「そうだ。普通にユーザー辞書があるじゃん」 と思って試してみた。
ユーザー辞書への登録は次のような感じ。
| よみ | 単語 | 品詞 |
|---|---|---|
\Pi |
Π | 名詞 |
\pi |
π | 名詞 |
\^1 |
¹ | 名詞 |
\_1 |
₁ | 名詞 |
\^alpha |
ᵅ | 名詞 |
普通のローマ字テーブルならひらがなモードからも入力できるんだろうけど,手持ちの環境は漢直の変な
運指表ということもあり,少し試行錯誤した結果半角英数モードにすることで確実にうまくいくことが分かった。
ということで,問題はMozcの辞書にどう入力するかだが,ユーザー辞書のテキストエクスポートとか試した結果, utf-8のテキストで
\Pi<tab文字>Π<tab文字>名詞⏎ \^3<tab文字>³<tab文字>名詞⏎ ...
のようなテキストでOKみたい。 なら,Julia言語で楽に作れそうだ。
インストールしているJuliaの標準ライブラリのREPLのソースでLaTeXの入力テーブルを探してみる。
JULIAROOT/share/julia/stdlib/v1.10/REPL/src/latex_symbols.jlあたりにあった。辞書だけあってDict型だ。
ならわりと簡単に実装できそう。
using REPL open("mozc_julia_latex_dict.txt", "w") do io for (key, value) in REPL.REPLCompletions.latex_symbols println(io, "$(key)\t$(value)\t名詞") end end
という感じで簡単なスクリプトを書いて実行してmozc_julia_latex_dic.txtというテキストファイルを作る。
そしてMozcの辞書ツールから「選択した辞書にインポート」ぐらいで読み込み完了。
次のgifが実行例だが,元からそういう機能があったように動作し,学習や先読みも効くので 本人がかなり入力にとまどっているのが分かるかと思う。
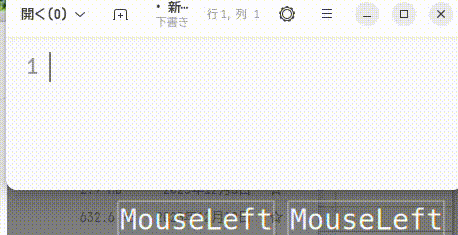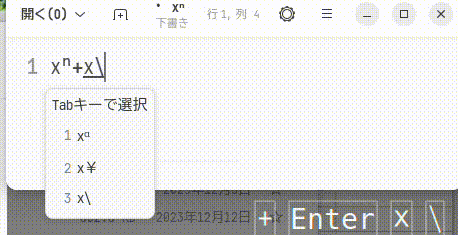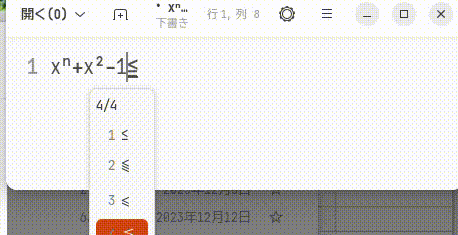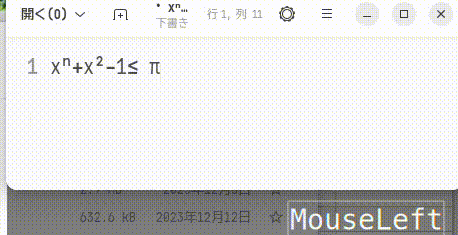
MS-IMEでも試そうとしたが
よみを全角(?)にする必要あり- UTF-16LEに変換する必要がありそうだが機械的に変換してもうまく登録できない
少し苦労すれば何とかなりそうな気もするけど面倒だし多分自分は使わないので諦めることにする。