※ この記事は漢直アドベントカレンダー 2025 9日目の記事になります。
はじめに
論文等から紐解くT-Code。第2回は「補助入力」編です。
T-Codeはどんなに目一杯テーブルに設定しても1500弱(tc.elの場合)ぐらいしか入力できません。 それ以外の漢字は補助入力を利用することとなります。
東大の研究グループでも補助入力方法の研究が進められ
- 部首合成変換
- 交ぜ書き変換
の二つの補助入力方法が提案されています。 これらについては「tc.el」をはじめとしたそれぞれの漢直入力環境で利用することが可能となっています。
今回は,論文を参照しながら簡単にその内容について説明していきます。
部首合成変換について
部首合成変換の補助入力用打鍵としては, 「右人差指ホーム→左人差指ホーム」となっていることが多いです。
部首合成変換についての最初のアイデアについては文献1に記述があります。 ここでは,基本文字を1200文字として部首の組み合わせで,後50文字程度漢字を追加すれば JIS第一水準漢字は大体カバーできると述べられています。
その後,1990年に文献2の論文が書かれています。この論文は部首合成変換 (論文のタイトルでは字形組み合わせ法で,論文内では厳密には部首ではないものも含まれているので字形組み合わせが正確な表現) の詳細の仕組みについて説明されています。
基本的には次の4つのパターンのように変換するらしいです。
- k ← V + W
- k ← v + w, L = x + v, M = y + w
- k ← v + W, L = x + v
- k ← L - X, L = k + X
1.のケースでは,基本文字VとWがあって,その二つの部品がkに含まれる時kという漢字に変換する, といった感じで変換をします。
1.とかだと除 ← ア + 余 2.とかだと徐 ← 待 + 除,3.とかだと徐 ← 除 + 余,4. 余 ← 除 - ア
ということでほとんどのケースが足し算,4.だけ引き算のような形の文字を出力するという感じです。
技術的には色々あるのですが,(というか自分で実装するとなるとなかなか難しいと思います。) イメージとしては納得しやすい変換原理かと思います。
では実際に部首合成変換の例を見てみます。最初は動画にしようかと思っていたのですが,逆に分かりづらいと思ったので,スクリーンショットで説明します。
漢直WSでの例
今となっては一番ポビュラーな漢直WSでの変換例です。前置式の部首合成変換は機能として持っていないので、 後置式部首合成変換となります。また,一度変換したものは自動で部首合成を行う機能もあります。
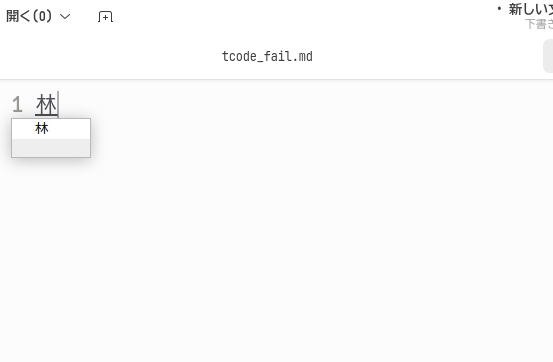
最初は「林」を入力する例です。T-Codeはこんなに簡単な漢字でも直接入力することはできません。 この辺りはTUT-Codeが常用漢字全てをカバーするのとは違うところです。
まず,「木」と「木」を入力します。
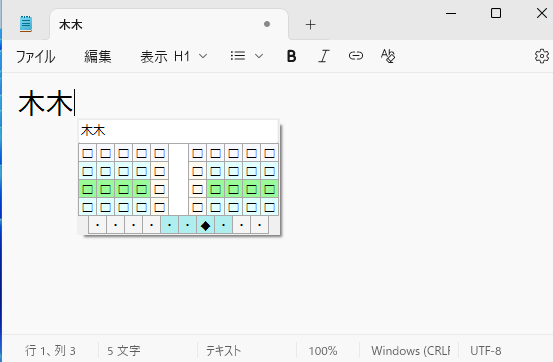
次に部首合成変換用の運指である右人差し指のホーム→左人差し指のホーム(Qwertyの場合j→f)と入力します。するとカーソル直前の2文字を合成して「林」と変換されます。
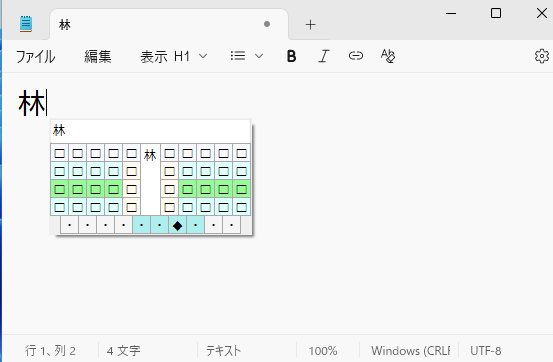
漢直WSの場合は一度変換した部首合成変換を自動で入力するモードがあって,便利に利用することが可能です。
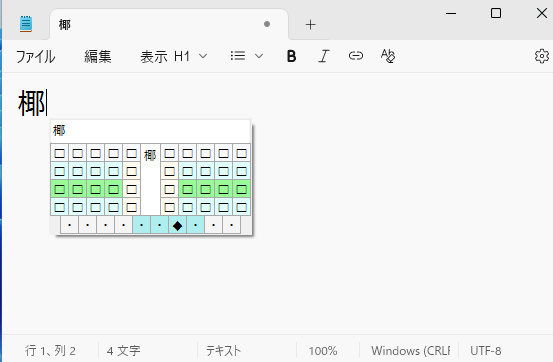
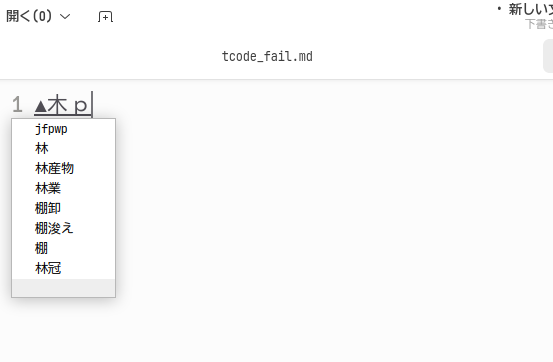
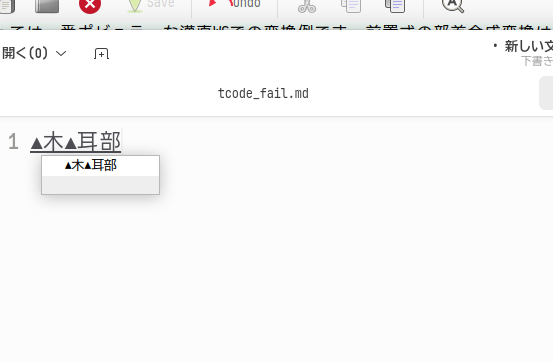
複数の漢字から部首合成変換を行うことも可能です。T-Codeで「椰」の文字を部首合成変換で入力する方法について説明します。それぞれ入力可能な「木」「耳」「部」を入力します。
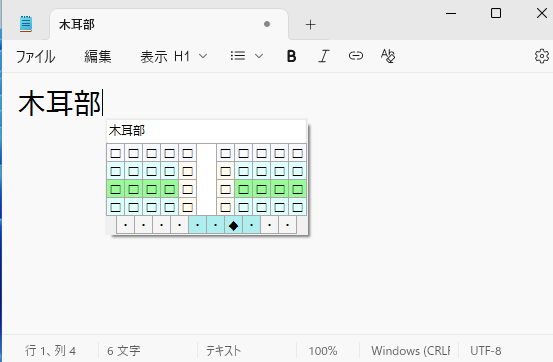
この状態で部首合成変換の操作j→fを入力するとカーソル直前の二文字を合成して耶と変換されます。
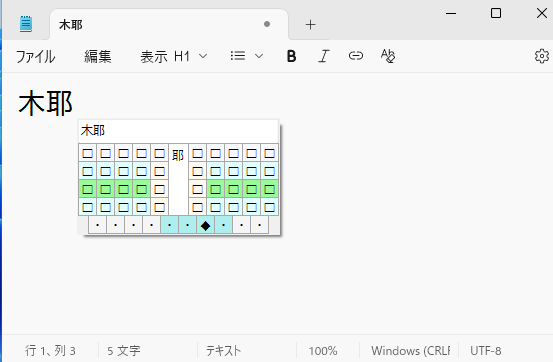
この状態でさらに部首合成変換の操作j→fを入力すると「木」と「耶」を合成して「椰」と変換されます。
tc.elでの例
これは自分の主戦場,tc.el上での変換例です。 私の場合はMozcでの模擬的部首合成変換に合わせるため,前置式部首合成変換を利用しています。
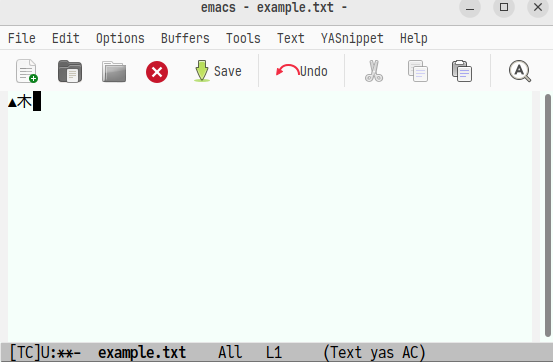
「木」+「木」→「林」と変換する例になります。前置式部首合成変換の場合は,変換前に
j→fを入力して,あらかじめ部首合成変換モードに入るイメージです。
j→fを入力すると「▲」のマークが表示され,その直後の二文字から文字を合成して変換します。
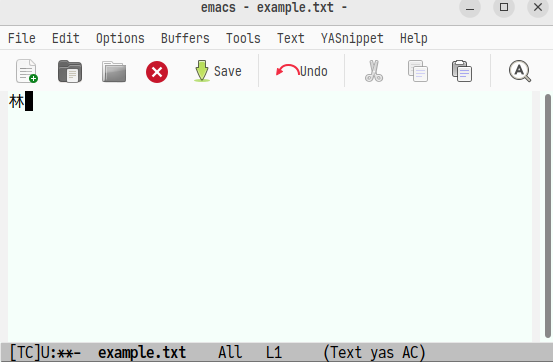
2文字目の「木」を入力した直後に「林」に変換されます。
次に,先ほどの「椰」の字の入力例について説明します。
部首合成変換モードに入って「木」を入力し,さらにその後の二文字を合成したものについて 合成することを宣言するため更に部首合成変換モードを重ねて「耳」を入力します。
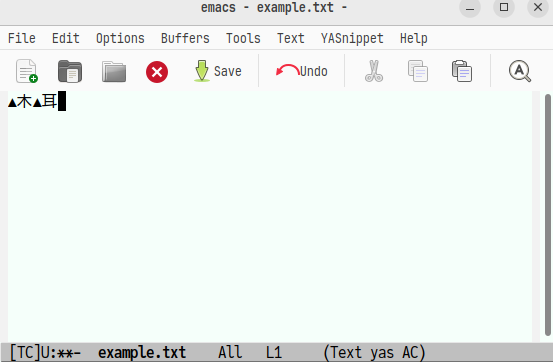
その後「部」を入力すると,即座に「椰」と出力されます。
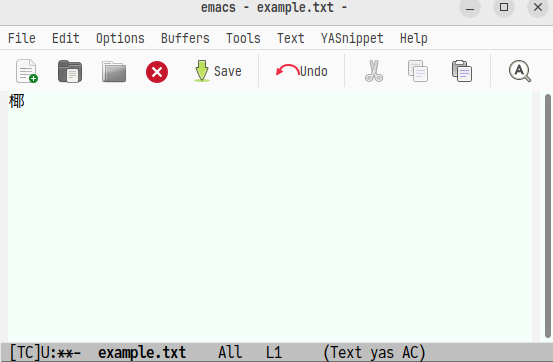
このように,前置式の変換については入力する前に頭の中で合成したものを思い浮かべる必要があるため,後置式の方が好まれているような気がします。
Mozcでの例
私がEmacs以外で利用しているMozcによる部首合成変換の例です。 実はtc.elの変換結果を手作りで作成したというよく訳の分からない例になります。 ただ,部首合成変換は実際に自分の変換してみないと覚えられず,連想式の漢直に近い感じかと思います
実際に,ラインプットでも46×46→2116字(数字や英字も含む)で入力できないケースは 二つの漢字での組み合わせ入力を利用しているとの説明3があるので, それと同じ感じかと思います。
「林」を合成する例です。ローマ字変換テーブルを利用しているため,漢字を入力している途中は素の英字が見えています。二文字目の木の一打鍵目まで入力した状態が次の画面です。
ここから木の2打鍵目である左手薬指上段を入力すると次の通り変換されます。
IMEによるローマ字入力による入力なので,未確定の状態になっているのが面白いところです。
後,Mozcでのローマ字変換テーブルについては最大1万件の制限があって, T-Codeでは直接入力できる文字数が1350件ほどあって,自分が利用している方法だと入力途中を見せる方式なので 中間データを登録する必要があって,余分に件数を使うこともあり,現状では 直接入力できない常用漢字を一通り入力できる程度しか登録できていません。
なので,椰は入力できません。まあや子と入力して後述する交ぜ書き変換をすると入力できるので,
実際に利用するケースではそんなに問題はないかなぁと思っています。
交ぜ書き変換について
交ぜ書き変換は「かな漢字変換の漢字が交ざったバージョン」と考えれば大体そういう感じです。 なので,分からない漢字は平仮名で,分かっている漢字はそのまま直接入力するように入力し, 通常のかな漢字変換のように変換します。
ただ,T-Codeにおいては一意に決まる部首合成の方が重要で交ぜ書き変換は複数の候補が出る可能性があるので, やや下に見られる傾向にありました。
また,活用形の扱いがこの頃のプアなPCのリソースということもあり限られた対応になってしまうこともありました。
また,TUT-Codeにもこの交ぜ書き変換についての論文4論文5があります。どちらかというと実装の工夫だけで, 基本的な交ぜ書き変換の考え方はどの論文でも変わりがありません。
ただ,TUT-Codeは基本的に3打鍵で入力できる漢字を含めると常用漢字全てをカバーしているので, 交ぜ書き変換はあまり重視されず「初心者向け」という位置付けだったようです。
どの論文においても,この頃のコンピュータのプアなメモリと速度の中でどう実装するかに主きが置かれていたような感じでした。
ただ,漢字が入力できることによって,変換候補の数を大幅に減らすことができます。
有名な交ぜ書き変換の例として
きしゃのきしゃがきしゃできしゃした
があります。T-Codeでは「貴社」が直接入力できません。
入力候補として「き社」と入力すると,「社」で候補がしぼられて,「貴社」と「帰社」の二つまでしぼられます。 また,入力候補として「き者」と入力すると候補は「記者」の一つだけとなり一意に変換できます。
「き車」の場合は「汽車」の一つのみ,「き社」は「貴社」と「帰社」の二つから選ぶ感じになります。
それを二つの実装で確認してみましょう。
漢直WSのケース
まずは「き社」と入力してf→jと入力します。すると次の画像のようなユーザーインターフェースが表示されます。
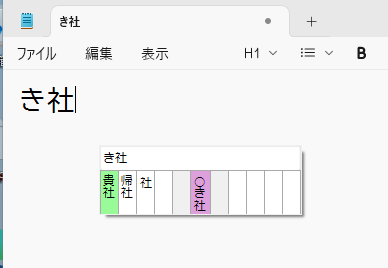
中央のピンク色のマスの両側にそれぞれ5つの箱がありますが,これは中段のキーを表していて,そのキーを入力することで候補から文字列を選択することができます。
また,Enterを押すと緑色の文字を入力して確定じゃないかと思います。
ここではEnterもしくは左手小指を押して確定させ,次に「のき者」と入力して,f→jと入力すると,次のような面画になります。
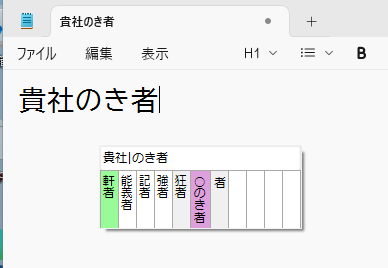
その前の「貴社」変換の直後に区切りがあるので,Enterを押すと「軒者」が選択されるようになっていますが,ここでは「記者」選びたいので左中指を押して「記者」を選択します。
その後「がき車」を入力してf→j。次のような画面になります。
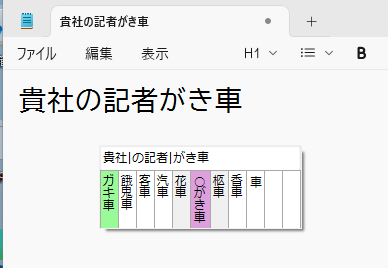
左人差し指のところに「汽車」があるのでそれを選択します。さらに「でき社」と入力して
f→j。
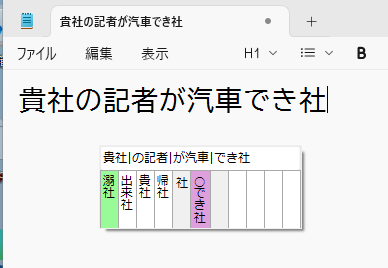
「帰社」(人差指ホーム側)を選択します。というような感じで確定していきます。
tc.elのケース
Emacs上のt-code環境tc.elの場合は部首合成変換は次のようなインターフェースになります。
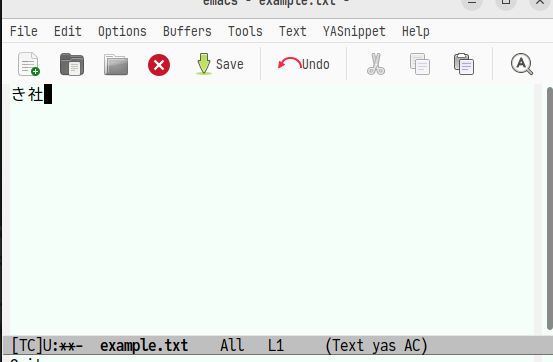
ここでf→jと入力すると次のような画面になります。
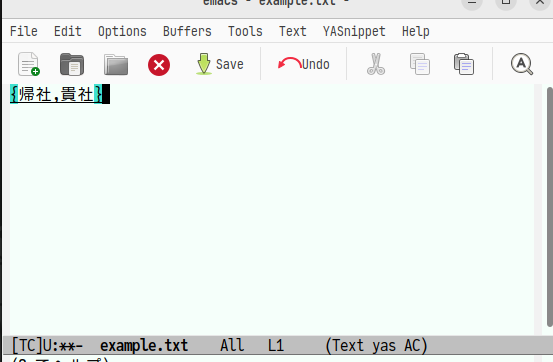
「き社」の候補が2つしかないので面画のように表示されます。この時,左側を選択する時は左手中指、右側を選択する時は左手人差指の中段キーを押します。
ここでは,「貴社」を選択するので左手人差指のホームを押します。そしてそのまま「のき者」と入力します。
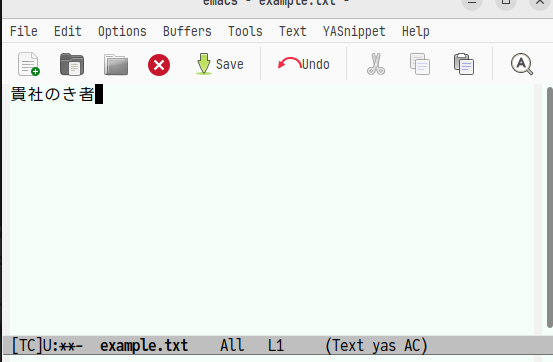
そしてf→jと入力すると次のような画面が表示されます。
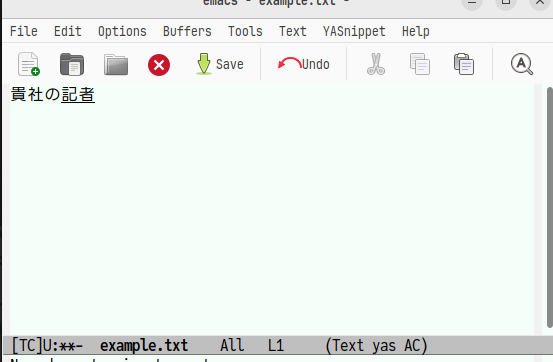
交ぜ書き変換辞書内に「き者」の候補が1つしかないのでそのまま「記者」と表示されます。 ここでEnterを押すと確定されます。そして,「記」は直接入力可能な漢字なので「直接入力する方法もありますよ」的な感じで下に入力方法が表示されます。
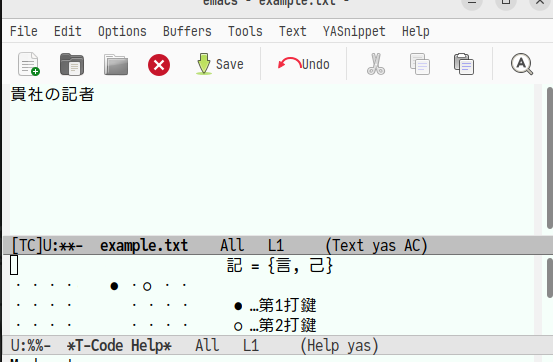
「がき車」を追加で入力します。
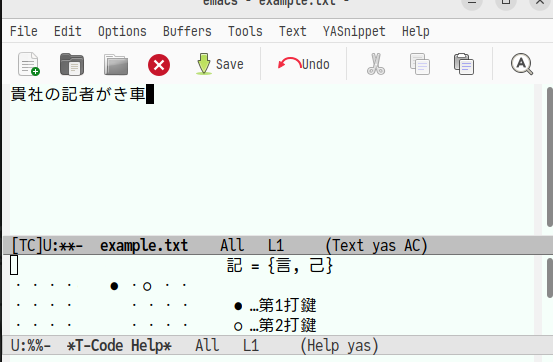
ここでf→jを入力すると次のような画面になります。
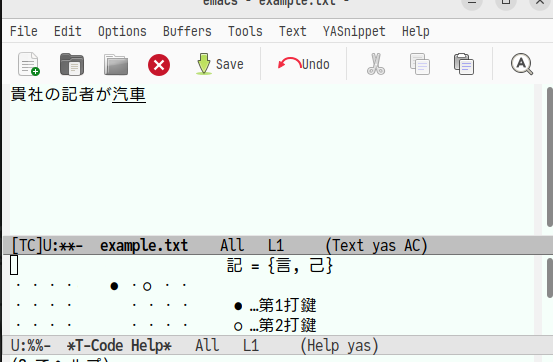
ここでも「き車」の候補が一つだけなので一つしか表示されません。Enterで確定します。
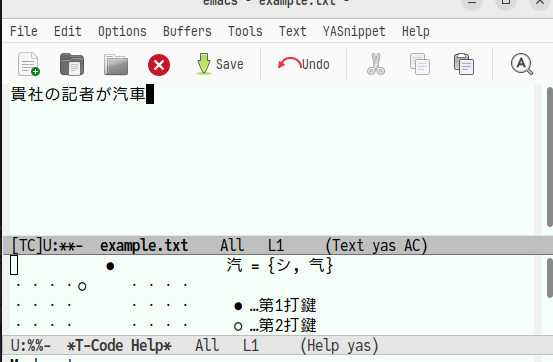
下に「汽」はこうですよ的に入力方法が表示されます。
さらに「でき社」と入力します。
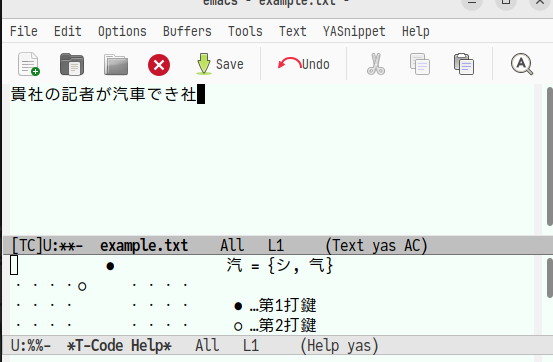
ここでf→jを入力すると次のような画面になります。
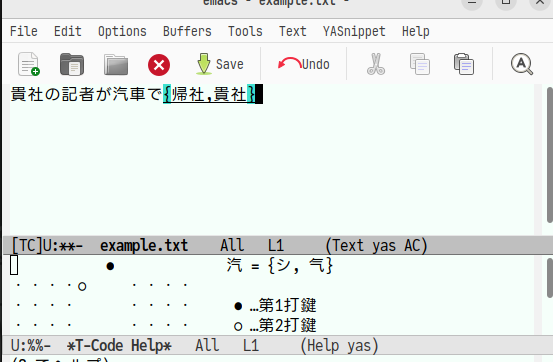
「帰社」を選択するため左手中指を押します。
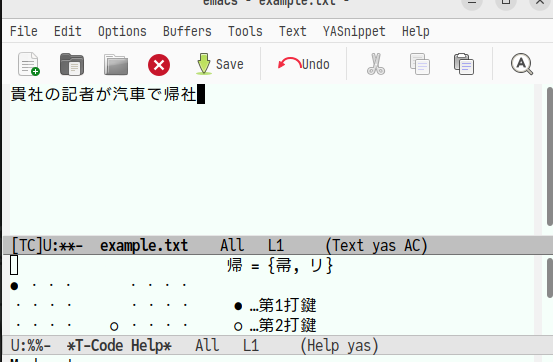
すると「帰」は直接入力可能な文字のため下側にヘルプが表示されます。
という感じで,Emacsのtc.elはヘルプ機能が追加されている感じです。 エディタの機能として実装されているので,そのあたりは便利に利用することが可能となっています。
さいごに
今回はT-Codeの補助入力方式として部首合成変換と交ぜ書き変換について紹介しました。 といっても最初に少し論文の一部を紹介しただけで現在の入力インターフェースの例の方が参考になったかもしれません。
それだけ現在の漢直用ユーザーインターフェースはT-Codeの論文で書かれている内容を忠実に再現しているといえるのではないかと思います。
今回の記事については以上です。
それではまた。
- 小野 芳彦,平賀 譲,山田 尚勇: 2打鍵日本文入力タイプライタにおける外字入力の一方式, 情報処理学会講演論文集 第23回全国大会(昭和56年後期).2 p963-96↩
- 小野 芳彦: Tコードの補助入力: 字形組み合わせ法と交ぜ書き変換法, 情報処理学会論文誌 31-3, p. 404-414, 1990 ↩
- 川上 晃, 川上 義: タッチ打法による漢字入力, 情報処理 15-11, 1974↩
- 2ストローク入力用仮名漢字変換システム, 情報処理学会研究報告ヒューマンコンピュータインタラクション, 1988-3, p. 1-8, 1988↩
- 2ストローク入力のための仮名漢字変換, 情報処理学会論文誌 33-7, p. 920-928, 1992↩