※この記事は漢直アドベントカレンダー 2025 の19日目の記事になります。
はじめに
すっかり順番が前後してしまいましたが, 今回は,ローマ字変換テーブルを利用した部首合成変換の実現方法について紹介したいと思います。
以前,スラドの日記に書いたこともあったのですが,もう無くなっているので再度の紹介となります。
今回のために少し漢直WSとかの設定画面とか覗いたのですが,Mozc用のローマ字変換テーブルが出力できるとあって, 今回紹介する必要はないかも,とか思っていたのですが,内容は自分にとっては使いにくい感じのものがありました。

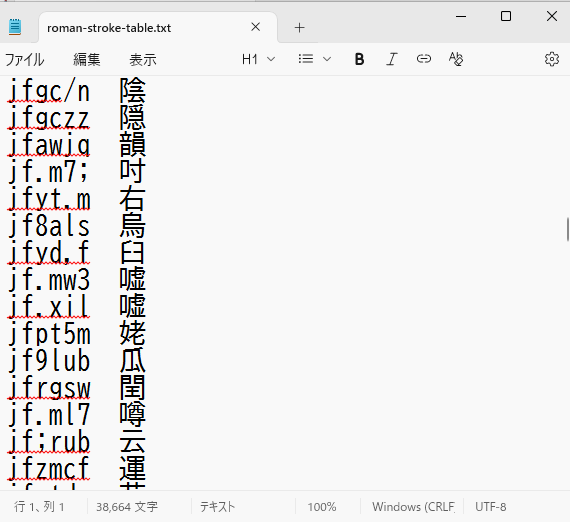
まぁ確かにそれでいいんだけど…という感じです。
やっぱり前置式部首合成変換といえば「▲」です。これを出しながら前置式部首合成変換を実現する方法について説明します。
Mozcの「次の入力」を使った前置式部首合成変換の原理
※次の内容は以前自分が書いた日記のパクりです。
さて,Google日本語入力のローマ字変換テーブルの設定には,「次の入力」とい うユニークな機構があります。
この機構を利用すると,いわゆる「携帯電話打ち」「トグル打ち」といわれる, 「1」を押すごとに 「あ」→「い」→「う」→「え」→「お」 というような入力を 実現できます。
この機構を使って試行錯誤することを繰返し,tc.elの前置式の部首変換を実現 しました。 以下の説明は,その設定方法の基本的な考え方です。
それでは「木+木→林」を登録する手順 について説明しましょう。 まず,「▲」 の登録をします。
| 入力 | 出力 | 次の入力 |
|---|---|---|
| jf | ▲ |
ここで,「▲」を「次の入力」に登録するのがミソです。そして次は「▲木」の登 録をします。 「pw→木」ですので,次のように登録します。
| 入力 | 出力 | 次の入力 |
|---|---|---|
| jf | ▲ | |
| ▲pw | ▲木 |
ここで,ポイントは「先頭に『▲』がある間は次の入力がある」という風に google日本語入力に認識させることです。 そして最後に「林」でフィニッシュ です。
| 入力 | 出力 | 次の入力 |
|---|---|---|
| jf | ▲ | |
| ▲pw | ▲木 | |
| ▲木pw | 林 |
先頭に「▲」が無くなると,確定出力の方に移します。
この設定で入力している文字列を見ると,
j → ▲ → ▲p → ▲木 → ▲木p → 林
となり,前置式部首変換モードに入って木と木を合成するというのがリアルタイ ムで分かりやすいのが明らかだと思います。
さて,この設定手順を見て「かなり大変な手間だ」と思った人も多いでしょう。 まぁ実際大変です。 ですが,前夜に紹介した「ローマ字変換テーブルのテキス トファイルのインポート・エクスポート機能」 を使えば多少楽になります。
といった感じで登録すればtc.elの雰囲気で部首合成変換が可能です。
部首合成する文字の選定
選定の方針
とは言うもののローマ字変換テーブルに登録可能な件数は無限ではありません。 現在利用しているものでは1万件の制限があります。
直接入力できるのが1350件ほど,今回採用する方法だと中間コードを吐くので, その余りの半分ほどしか登録できません。
そこで,直接入力できるおよそ1350文字を除いた3,000字ほどを選定することとします。
ネットで利用可能なN-gram情報として,N-gram コーパス - 日本語ウェブコーパス 2010があります。
利用条件も特にありませんし,これの1-gram情報を利用してみましょう。
頻度順への並び替え
さて,ここでも自分がよく使うJulia言語を利用して情報を加工していきます。
わりと面倒なのですが,DataFramesモジュールを利用しています。
using DataFrames # 「1gm-0000」というファイルを一行一要素の配列で読み込んで # その行ごとにタブ文字列で分割 str_lines = split.(readlines("1gm-0000"), "\t") # それぞれの配列の一要素目を文字として抽出 文字s = map(x -> x[1], str_lines) # それぞれの配列の二要素目を頻度の数値として抽出 頻度s = map(x -> parse(Int64, x[2]), str_lines) # 1列目を文字,2枚目を頻度した表を作成 df_1gm = DataFrame(文字=文字s, 頻度=頻度s) # 頻度の逆順でソート sort!(df_1gm, [order(:頻度, rev=true)]) # 漢字のみの表を抽出 df_1gm_漢字 = filter(:文字 => x -> contains(x, r"\p{Han}"), df_1gm)
頻度順のトップ10は次の通りです。
</S>と<S>はそれぞれ文の終わり,文の始まりを示します。
集計方法の関係で句点がないことに注意が必要とのことです。
読点が5位にランクインしているのが興味深いですね。
julia> first(df_1gm, 10)
10×2 DataFrame
Row │ 文字 頻度
│ SubStrin… Int64
─────┼───────────────────────
1 │ </S> 5634102353
2 │ <S> 5634102353
3 │ の 4989732831
4 │ い 3660604274
5 │ 、 3101635837
6 │ に 2841944679
7 │ し 2744502961
8 │ て 2685693429
9 │ で 2611700100
10 │ た 2492795128
julia>
次に漢字のみのトップ10です。
といっても,鉤括弧とか中点とか上位を占めています。
正規表現の\p{Han}で引っかけるとこういった文字も入ってくるようですね。
julia> first(df_1gm_漢字, 10)
10×2 DataFrame
Row │ 文字 頻度
│ SubStrin… Int64
─────┼───────────────────────
1 │ 、 3101635837
2 │ ・ 973730033
3 │ 「 537820260
4 │ 」 496905383
5 │ 人 452873094
6 │ 日 450607543
7 │ 大 327964488
8 │ 一 320862498
9 │ 本 286611008
10 │ 出 273077295
直接入力できる文字等の除外
次に漢直アドベントカレンダーの14日目の記事で準備した
tcode.stファイルから直接入力可能な文字を抽出して部首合成ではそれを除きます。関数の仕組みに関しては14日目の記事を参考にして下さい。
また,今回はEmacsのtc.elの部首合成変換結果を利用するため,JISの第1,第2水準の漢字のみ取り扱います。
なので,jis_1st.txt,jis_2nd.txtとして,
githubのgistにあるテキストファイルを利用させていただきます。
ar_1st = split(read("jis_1st.txt", String), "") ar_2nd = split(read("jis_2nd.txt", String), "") # "丶"は処理に困るのであらかじめ取り除く deleteat!(ar_2nd, findfirst(x-> x == "丶", ar_2nd)) ## 直接入力可能な文字の配列 tc_ar = filter(x -> x != "", read_tcode_st("tcode.st")) # 漢字かつ 直接入力不可 かつ (第1か第2水準漢字に含まれる) ものを抽出 df_1gm_ext = filter(:文字 => x -> contains(x, r"\p{Han}") && x ∉ tc_ar && (x ∈ ar_1st || x ∈ ar_2nd), df_1gm)
内容の方を確認してみます。
julia> first(df_1gm_ext, 10)
10×2 DataFrame
Row │ 文字 頻度
│ SubStrin… Int64
─────┼─────────────────────
1 │ 載 49225887
2 │ 覧 37709262
3 │ 像 34653290
4 │ 俺 30325239
5 │ 歌 28049558
6 │ 皆 27868452
7 │ 馬 27782998
8 │ 泉 26082271
9 │ 頂 25402564
10 │ 松 25066191
julia>
このdf_1gm_extの先頭から3000字の部首合成変換情報を抜き出します。
部首合成変換テーブルの作成
Emacsのtc.elから部首合成変換情報の抜き出し
Emacsにはemacsclientという既に起動しているEmacsとの情報をやり取りする仕組みがあります。
これを利用すると,実行しているEmacsに対してコマンドを実行することで,そのEmacsでの部首合成変換の
結果のようなものを取得することが可能です。
ただし,Emacs側で,
(require 'server) (server-start)
をあらかじめ実行する必要があります。
さて,Julia言語側で部首合成のヘルプ文字列を取得してみます。次のような関数を定義します。
function get_bush_help(文字) options = ["(tcode-help-bushu-help-string \"$(文字)\" t)"] read(`emacsclient -e $options`, String) |> x -> strip(x, ['\"', '\n']) end
実行すると,その文字列によって結果が変わります。
julia> get_bush_help("林")
"木 + 木"
julia> get_bush_help("椰")
"木 + (耳 + 部)"
ただ,tc.elのヘルプ関数はあまり精度が良くありません。
そこで,上記のような入力可能な二文字のみの組み合わせの時はそのまま採用,
上のように複数の文字を複合しないといけない時は,以前入手していた
入力可能な文字どうしでの部首合成総当たり結果を使って,自分が
一番使いたい二文字の組を人力で抽出するものとします。面倒臭いですが。
res_ar = [] for k in 1:3000 the_str = df_1gm_ext[k, :文字] x = get_bush_help(the_str) push!(res_ar, [the_str, x]) end res_ng = filter(x -> contains(x[2], ")"), res_ar) res_ok = filter(x -> !contains(x[2], ")"), res_ar) # 人力で確認した部首合成変換用文字列その1 ext_strings = [ "皆比白", "亡忘心", "騒駅虫", "忍切心", "奨将大", "傍位方", "恒慢二", "呪喜ル", "膝月委", "偵側ト", "國国残", "敦享故", "謗訪立", "揉採予", "萬芝遇", "憑駅心", "喝域掲", "櫻桜側", "蕉サ確", "嗜唱老", "嗅喫自", "藪藩故", "拗オ後", "鰹魚賢", "樫木賢", "栞併木", "喩輸ロ", "傲イ教", "絢約日", "傭備広", "諫言頼", "瀕瀬歩", "蓼茶参", "麿麻営", "傳仏博", "筍答包", "羹羊羊", "筐竹区", "楢横配", "澱汎展", "薯著四", "惠ム恵", "藏緊サ", "賤残買", "櫃木遺", "擲オ尊", "滓シ章", "埜禁土", "攀橋挙", "聰取因", "悍慢刊", "嗤ロ謡", "娑渉女", "鈎鉱句", "涵汚画", "鵡武鳥", "勁災功", "誼詑助", "瀟津サ", "俟候ム", "齟歯助", "荀菊日", "咫ハ択", "簗築切", "巖山警", "并併イ", "塹軽所", "莽サ井", "諡誇ハ", "濟消交", "蘂薬心", "樵集点", "礬礎大", "囂額エ", "姨女引", "堝過土", "洵混句", "劈避切", "櫟後禁", "枳格ハ", "櫚欄営", "茯花、", "燒焼土", "曉日街", "洟添引", "繞糸焼", "藥サ機", "喇整別", "滉況日", "葎サ書", "籔竹改", "扼オ印", "槓木側", "倫信論", "濱渉員", "膀龍方", "濤治寿", "疇副寿", "甕護互", "攫オ護", "贖則負", "幀帳則", "殘繊列", "刎制物", "價価員" ] # 人力で確認した部首合成変換用文字列その2 ext2_strings = [ "黍科水", "漆シ黍", "弟第ケ", "鵜弟鳥", "會へ日", "檜木會", "弟第ケ", "梯木弟", "剃弟リ", "頸災項", "斬車質", "漸シ斬", "鼡ツ用", "蝋虫鼡", "秦実科", "榛木秦", "窒空屋", "膣月窒", "朿刺リ", "棘刺朿", "屯ノノ", "艸山屯", "贊先員", "鑽金贊", "耶耳合", "椰木耶", "旁立方", "榜木旁", "齊交月", "臍月齊", "爭爪争", "箏竹諍", "黽電電", "蠅虫黽", "蕀サ刺", "朿刺リ", "棗蕀朿", "殿設展", "臀殿月", "旁立方", "蒡サ旁", "謁言掲", "藹サ謁", "尋寸ヨ", "蕁サ尋", "參ム参", "鰺魚參", "珀王白", "篁竹珀", "旱日干", "桿木旱", "悌性弟", "匡区王", "框木匡", "當尚田", "蟷虫當", "遣追中", "鑓金遣", "彎糸引", "灣シ彎", "殷白ヌ", "慇殷心", "芯サ心", "蕊芯心", "賓少員", "嬪女賓", "爭爪争", "淨シ爭", "朋月月", "萠サ朋", "眞ヒ具", "愼性眞", "經エ災", "輕車經", "黽電電", "繩糸黽", "瞿目進", "懼性瞿", "僉合ハ", "嶮山僉", "襄譲言", "讓襄言"] # res_okの結果から上記の配列の形式に変形します。 bushu_strings = map(x -> string(x[1], split(x[2], " + ")...), res_ok) # 文字列配列を結合して重複を取り除きます bushu_all = unique(vcat(ext_strings, ext2_strings, bushu_strings)) # ソートします sort!(bushu_all)
bushu_allには次のような文字列の配列になります。
julia> bushu_all
3008-element Vector{String}:
"且助カ"
"丕不一"
"丙一内"
"丞了水"
"个へ1"
"串中ロ"
"丼井、"
⋮
"齎月員"
"齟歯助"
"齢歯令"
"齧大歯"
"齬歯語"
"龜免メ"
で,さらに別のやつ(『とか』等の変換を加えたもの)とかこのファイルと以前紹介したtcode.st,keytbl.txtを使ってローマ字変換テーブルを
作成するものを作ったのですが,今回は割愛します。もう記事も長くなり過ぎたので。
使用例



さいごに
今回はMozcおよびGoogle日本語入力で前置式部首合成変換を実現する方法について説明しました。
Emacs上での作業っぽく実現できているかと思います。
しかし,なかなかうまくいかず時間がかかってしまいました。
一応作ったローマ字変換テーブルの例はこの辺りにあるかもしれません。
まだ自転車操業的な記事作成が続きますが,25日まで頑張ります。
それではまた。